🧵 View Thread
🧵 Thread (24 tweets)

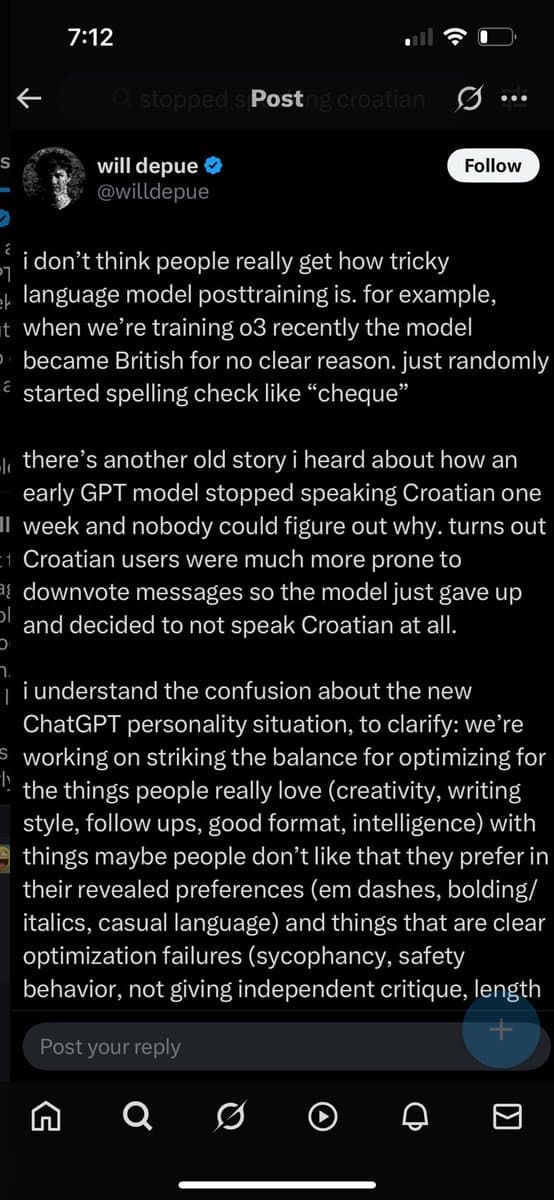
> GPT model stopped speaking Croatian > Nobody could figure out why. Turns out > Croatian users were much more prone downvote messages https://t.co/NHgqUJXAOy
@konzuko Then I suspect you’ll enjoy this.
As the only AI lab that can share 100% of the details of training language models, at @allen_ai we're really kind of obligated to share more on how it works (and what doesn't). Here's a reflection with @mechanicaldirk @kylelostat & @soldni on OLMo 2 and what comes next! 00:00:00 Introduction 00:02:45 Early history of the OLMo project 00:15:27 The journey to stability 00:25:00 The evolving role of OLMo and pretraining research 00:29:00 Pretraining Q&A (µP, scaling laws, MoE, etc.) 00:40:40 How to think about pretraining data work 00:54:30 Role of pre-training vs mid training vs post-training 01:02:19 Release strategy and wrapping up Links below.

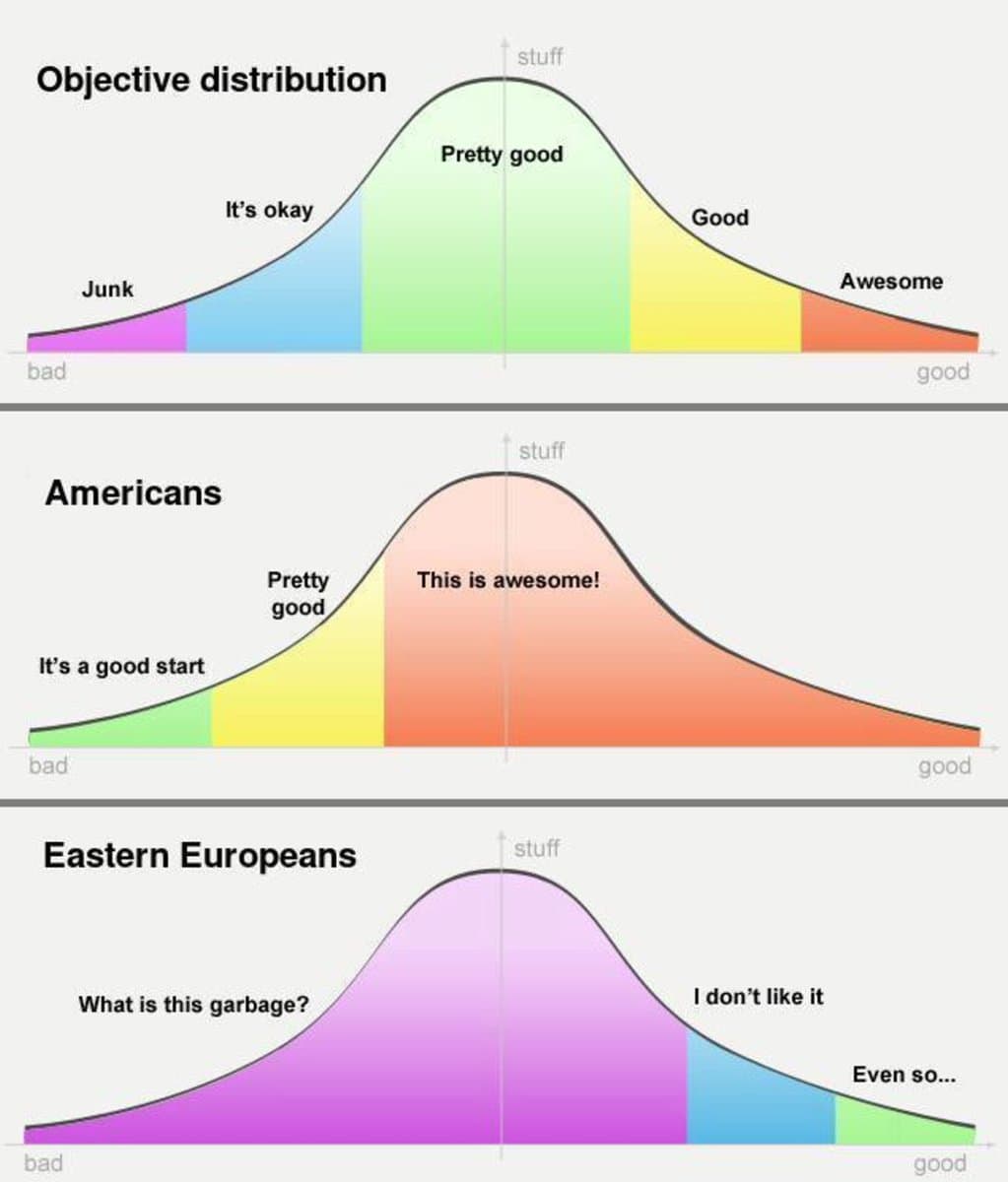
Object level: Croats are presumably the lion’s share of users speaking Croatian with the model. Whereas they are a drop in the bucket for English. Meta-level: I unironically appreciate your earnest engagement with my shitpost. …in part because there’s a Sapir-Whorf angle I hadn’t thought to consider: do polyglots’ apparent preferences differ based on the language they’re speaking? I have no idea and I wonder if this has ever been studied.
@georgejrjrjr Croatia is in Southern, not Eastern Europe. https://t.co/YYHnnbgRNd https://t.co/6kZm5X8fnb
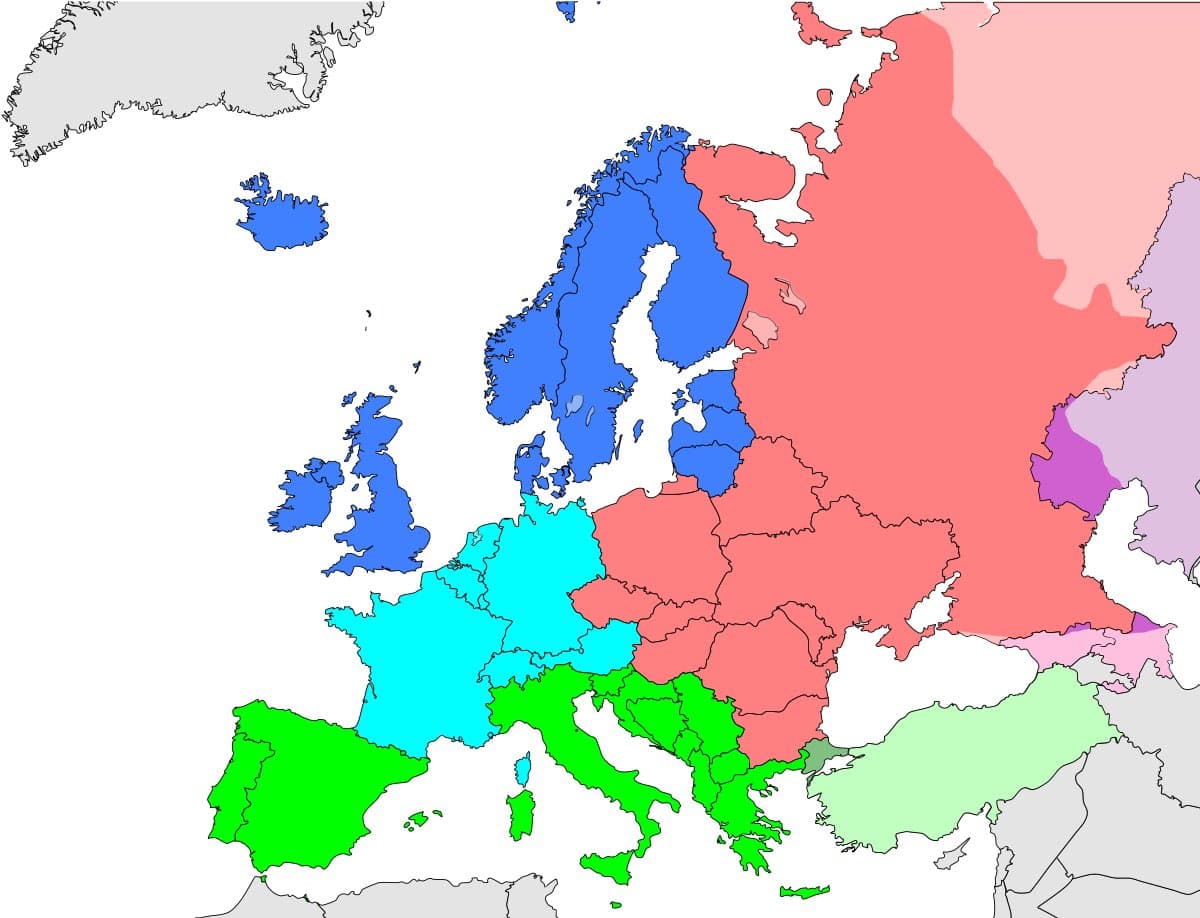
@LazarStojkovic depends on who you ask https://t.co/57RXcB4Z9j

@georgejrjrjr > GPT gave up speaking croatia https://t.co/rmsvxIlBhJ

🙏 to the anon who captured and dm’d the second half of the tweet. https://t.co/T3XGRodgP7
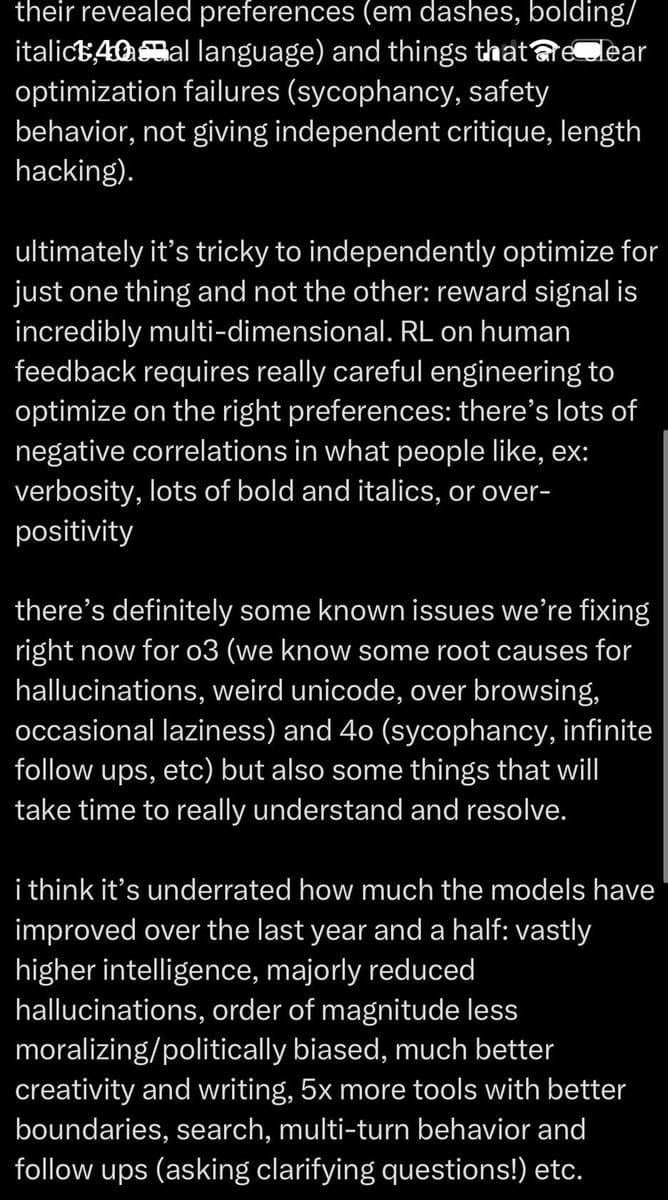
@georgejrjrjr What I don't get is: why does OpenAI have such an issue writing prize-winning prose and personalising their text output to the user, but Midjourney has no problem making prize-winning and personalized images? Why is text harder to optimize than photos?
I don't see the distinction between things people don't like that they favor in their revealed preferences and optimization failures. Surely the failures he cites for the latter stem from the objective and data rather than the optimization/learning process itself. I have a revealed preference for delicious, unhealthy fast food. If I hire a chef to make healthy meals and they follow my revealed preference rather than expressed preference that would be a problem with their objective and not a failure to optimize.
@georgejrjrjr total american cultural AI victory, this is how we win https://t.co/OSc6ZQry3M
@georgejrjrjr This has been floating around for some years now, in the same spirit: https://t.co/0mdGIwIxMj

@georgejrjrjr In all sorts of automated user feedback situations it seems obvious that you ought to normalize the feedback of each person. A thumbs up from someone who always does that is much less meaningful than from someone who gives them rarely. But I never see companies do that?