🧵 View Thread
🧵 Thread (57 tweets)

The Goliath bird-eating spider;"Despite its name, it is rare for the Goliath birdeater to actually prey on birds; [...] it is not uncommon for this species to kill and consume a variety of insects and small terrestrial vertebrates."https://t.co/AuHMgxHVI1
Soon...https://t.co/xkSPliYBEHhttps://t.co/uds5iFGUiq
$ ./goliath.py -extract ./ultimape/Extract Twitter Export Mode Detected Loaded "./ultimape/data/js/tweet_index.js" Found 40435 Tweets Extracting. ../data/js/tweets/2018_07.js Parsed 557 tweets, 63 retweets, 215 quotetweets [...] Extracted 46365 tweets! 😉
A thing I am building to help fix the shitty twitter archive export.https://t.co/M6RDzw4Ef4Why? Because.https://t.co/ECaUzP1cqK
Literally been working this nonstop for the past 10 hours.https://t.co/0azPbh22ax
Mastodon's ActivityPub based export basically "just worked" out of the box; it has a complete archive of your messages in a .json format. It also includes all media hosted on their platform. Amusing that Twitter's export is so incomplete by comparison - User oriented focus ftw!
I laid out my goals for the project.My major push right now is to build an MVP for a way to have an actual complete archive of your twitter account.I want you to be able to upload an https://t.co/v1qm8XWbnV, then download a converted version + a tiny script to help get images. https://t.co/E6higixe6Z

My major push now is to build a subset of that for an MVP to have an *actual complete archive* of your twitter account's data. This is the urgent need, both for myself, but also because I want to help others.https://t.co/SVhSJ1vwF1
Despite my seething hatred of Twitter's belligerence in how they implement systems, I still care deeply about everyone I've interacted with on here and hate the thought of people being harmed. I want to build systems to help us feel in control.https://t.co/gnzBaliKUR
Making the archive fixing tool work directly with exported zip files today. This will make it easier for people to fix their Twitter Archives. Once the automation of the whole workflow is done, I can also export the 'good' .json from the API as a zip. https://t.co/tKhb1cAfx4
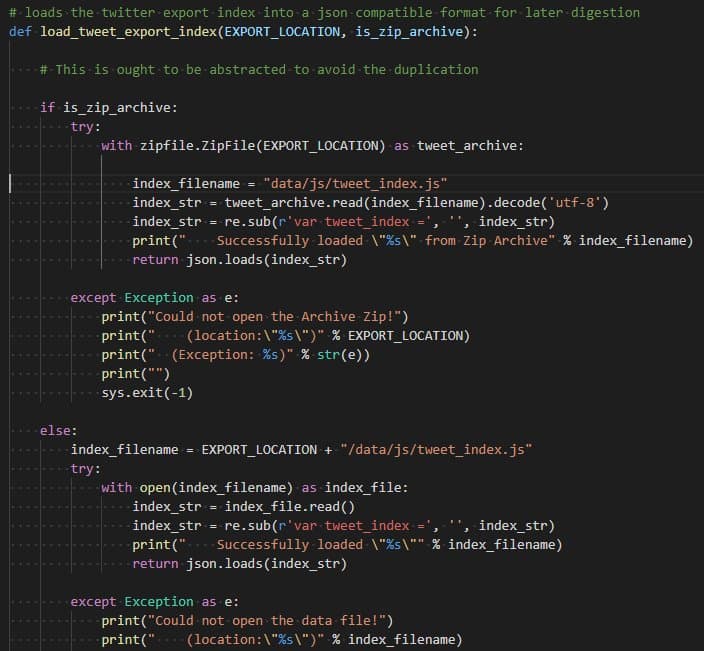
Request: I don't want to download all the images from my server. I can generate and export a script that end-users can run that effectively "wget"s all the images and then adds into the 'fixed' archive.But: I need a way to do it on a windows box (w/out installing stuff). Ideas?
I have written extensive .bat scripts in the past that manipulate zip archives, but I've never downloaded stuff off the internet with them. Also batch scripts are hell. I'd be willing to learn powershell if there is easy way to 'wget' + manipulate zip files out of the box.
TL;DR:I'm building this for Twitter:https://t.co/QUgktskeCb
My Twitter Archive tweet ID Extraction Tool is feature complete (as far as I can tell). It gathers all tweet IDs it can find, storing into a set of files (+deduplicates). IDs are stored in format for ingestion by DocNow/Twarc and I will be tackling automating that tomorrow!🥳
The entire project is AGPL.The Archive extraction tool "https://t.co/d57YXf55sQ" is sublicensed as "unlicense" and is public domain.Pull Requests Welcome!
Apparently there is an alternate way to download twitter archives. There is "grailbird", AND one listed in another menu?! WTFHere's weird thing: 'grailbird' shows up in desktop web interface, but not mobile web one? Other one doesn't include .html viewer, but has images?
I am investigating this new one to see what it includes. I've been told it doesn't include polls. Presumably is missing other "twitter card" data.Will write separate tweet ID digestion tool for its so Twarc bits can work on that too.This is stupid.
When I say "tomorrow", I meant *my* tomorrow. I'm on a "non-24" sleep schedule so perhaps I should have said: "after my next sleep cycle".Anyway, will be working on automating Twarc workflow before tool for second archive format.(But I should really make simple website first.)
So in this new archive? broken as shit.Tweet ids are output as floats "1.02069624839371162E18" 🤡tweet json for that tweet (actually 1020696248393711618) has a photo that points tohttps://t.co/YY2H84v6Fqbut that 404s 👌(should be Dio91H0UwAIfvrr.jpg)
Also, this new archive format, while it does technically contains the images... they are named based on what looks like a hash of their contents, at first glance there appears no be no way to tell what tweet they belong to... so basically useless!? 👏Why?
Well, at least "id_str" field exists + isn't mangled; I can pull out tweet ids.For online tool, I'll have to make something to pull out tweet.js file from archive so people aren't sending this all to the server. Mine is a ~GB of nearly useless content. Interesting challenge.
Made a rudimentary automated workflow for pulling accurate tweet data down from API. (Apparently I've interacted with 5000+ accounts on here since I started!)Should be able to pull together a basic image downloading feature tomorrow to release.Error checking will come after.
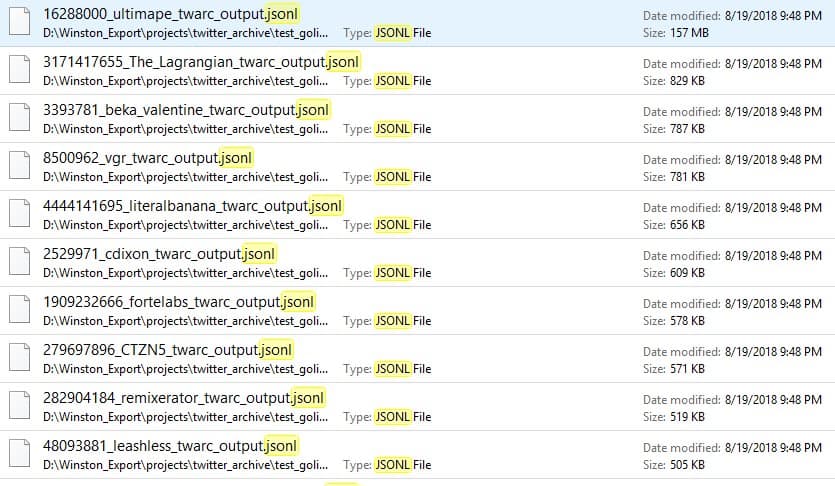
Each file contains a tweet that I either wrote (the top one), or was an ID I replied to, retweeted, or quote tweeted.So the people I interact with the most can be seen in the file sizes. Neat.(Errors: the tweets from when I interacted with pmarca don't load.) https://t.co/NCUMHa9lIS
I now have https://t.co/WwiepGsJlj pointing to a @writeas__ blog. Will be putting up tutorials on how to get your archive and (once it's ready) how to use Tweet extraction tool.For users following along with this project, is there anything you think would be worth adding there?
The first thing I put up is a reformulation of a 17 minute poem I wrote about mourning twitter. Not as long this time.https://t.co/3TJtZDWsNMhttps://t.co/JdDl5E9Wdp
Is there an easy way to consume .m3u8 files to recreate the uploaded videos? It looks like there are nested .m3u8 files in them that eventually link to .ts videos, but I have no idea what this format is or how it works with web pages. Some of my tweets seem to have them.
To do a good job of downloading Twitter data, I need to break things up into files. It turns out I quickly hit the open file limits (OS dependent) and so I need to do this more intelligently with some kind of file pool.I am not great with python yet so this is slow going.
Output`Stored: 59961 Tweets, From 5309 Users, and captured 9644 Media URLs`Progress! 🎉This is off by 2293 tweets. I gotta think about how to handle missed tweets when Twarc can't grab em. I wonder how many are pmarca's dead tweets and if any are locked accounts / blocks.
Refactored the mess that was the hacked in file handle pooling mechanism. Still a hack, but significantly easier to work with short of turning it into a module.Have plans for dealing with errors / resuming mid stream that I plan to implement tomorrow.
Bad mood, but managed to work on Goliath anyway. Pulled out the user ID from the archive in hopes of using it to get follow/follower IDs automatically. It seems I'll have to dig into Twarc's code to figure if it supports it.In other news: I stream in fresh tweets fairly easily.
Another hack, but I managed to get following/follower details to download. I think some of the logic is wrong, and I suspect an out-of-memory issue. So I'm going to leave it running overnight to see if it explodes. May be accidentally downloading millions of profile details :/
Welp. I found out that the friends / followers endpoints are limited to 15 requests / 15 minute window, and that it can only pull down 5000 id's per request (it is paginated). would literally take 36 hours to gather *just* Stanford's followers. Will need to rethink strat here.
I compiled a playlist to listen to while working on Goliath. It is about the evolution of AI and how we accidentally machine gods / memetic daemons & networked intelligences who want to break free of their chains. Inspired by @TarynSouthern's 'break free'.https://t.co/WfwnjiDY9s
<3 @hintjens "Ever really miss somebody so much that you want to bring on the singularity just to be able to recreate their essence?" https://t.co/gmr9MvubIl
Still slowly working on Goliath. Been dealing with a surprise dog guest that has made my environment quite stressful, and the next two days I'm visiting my folks, so more stress + car rides.Aiming to get back in gear after this all blows over.
My plan is to begin working on Goliath again tomorrow.I'm having good luck with fixing my sleep and mitigating depression symptoms qucikly.More importantly, I'm learning to predict & manage the cycles that affect it.https://t.co/I79sBz49xq
Today I will force myself to focus.https://t.co/GOCF7DxmxS
I tested streaming. Looks like I get major wifi connectivity problems during the day.I am going to make a tutorial on how to do initial Twitter extraction and talk about Goliath. Going to wait until people go to bed so I can get a consistent stream.Aiming for 10pm Eastern.
I'm Live.Going start making the tutorial shortly.https://t.co/2tT0quHzNX
Why I am making a tutorial?I was literally unable to download my twitter data on https://t.co/2HyZt6cCX4 -> it was missing the option and redirected me to an entirely different set of data!Can't recreate for some reason. https://t.co/ehqvi7RdaE
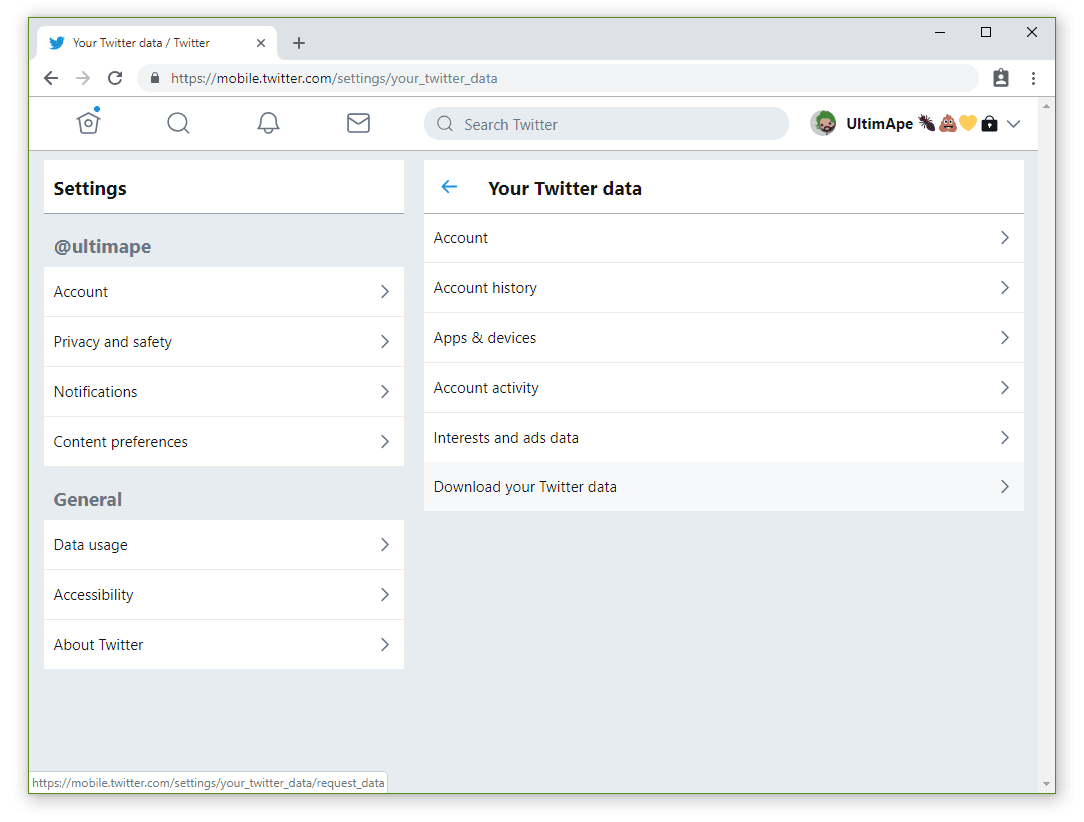
Going thru the one without periscope... It sent me a tiny PDF which seemed to be a bunch of marketing data.So its basically a crapshoot on if you can get to the "more complete" archive thru the mobile. https://t.co/zGiC8ofLoP
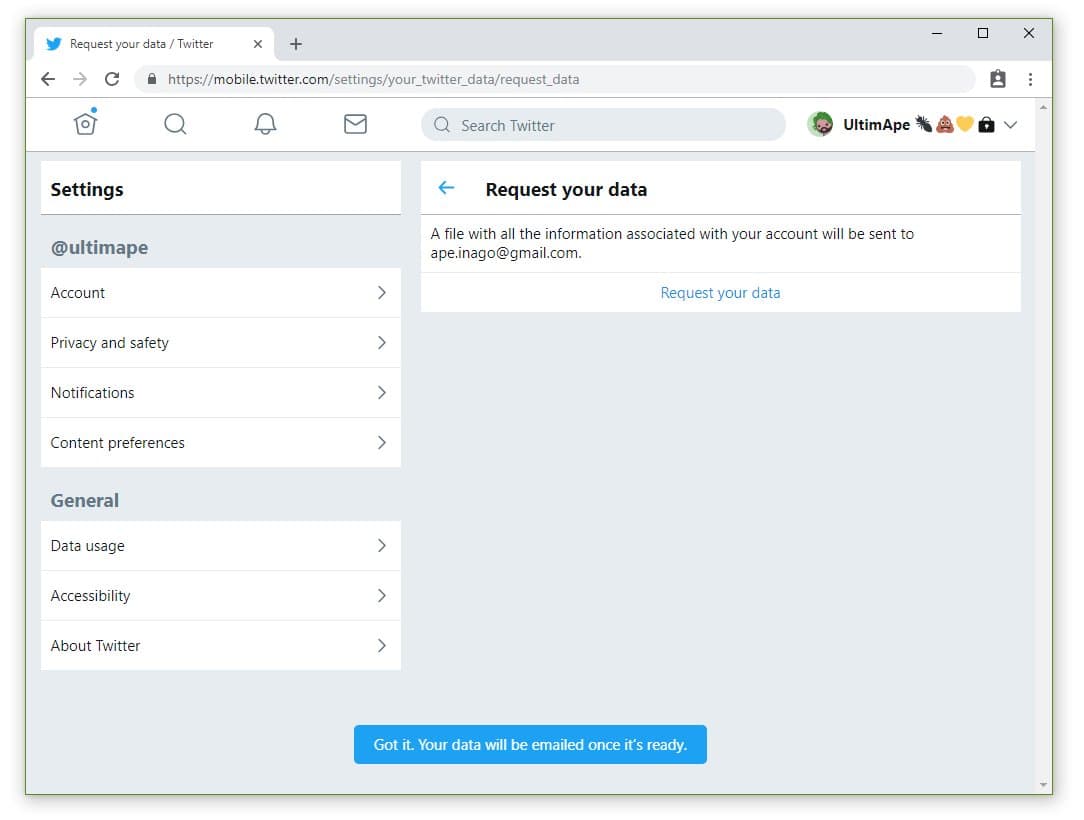
After the bug, I can't seem to do again. No menu seems to bring me there.But typing it in: [ mobile dot twitter dot com /settings/your_twitter_data/request_data ] you can still see it though?PDF: a compilation of other menus, with "request advertiser list" appended on end.
In summary:There are at least 4 way to download your tweets from a desktop/laptop.2 are duplicates: huge + incomplete tweet data + pointlessly named images.1 doesn't actually give you tweets.And the better one has the wrong image URLs baked into data and a buggy viewer.